用户实践
TiDB 在二维火餐饮管理实时报表中的实践
作者介绍:火烧(花名),二维火架构运维负责人
二维火 SaaS 平台介绍
二维火作为餐饮商家管理标准化服务提供商,帮助商家节省经营成本、提升服务效果是我们的使命。在商家日常生产中,上游系统产生了很多数据,包括供应链采购系统(Support),门店收银系统(POS),食客排队系统(Queueing),智能厨房显示系统(KDS),电子菜谱系统等(E-Menu), 一个实时、精准、可多维度分析的报表系统能充分利用这些数据,支持商家对经营决策进行优化,极大提升商家工作效率。主要服务于以下场景:
-
收银员交接班需要通过收银软件、财务报表进行多维度对账,来保障收银员一天的辛苦劳动。
-
商家运营人员需要时段性监控每个门店的经营状况,并通过监控数据实时调整运营策略。
-
中小型店老板解放自我,不再需要时时刻刻呆在门店里,也能从原料变化到收入波动进行实时把控。
-
大型门店连锁更有专门的指挥中心,实时了解每个门店的经营状况,实现一体化管理。
二维火各类报表界面:
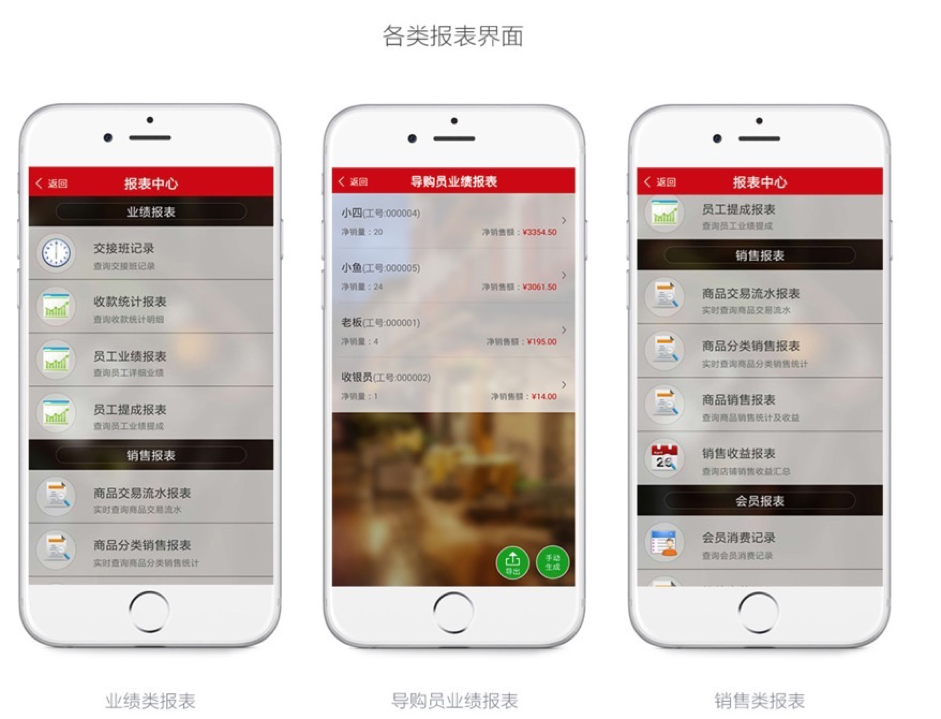
二维火实时报表的业务约束
-
要求实时或者准实时,数据延迟不超过 3 秒。
-
数据量大、数据增速快,报表结果查询需要在 500 ms 之内返回结果。
-
查询维度多,查询条件复杂,涉及十几个业务表,上百个维度汇总查询。
随着业务范围扩大以及功能扩展,实时报表业务不光承担了报表业务,业务方同时希望这是一个数据实时、可多维度查询分析的数据平台工具,为业务进行各种数据支持。
二维火数据的特殊场景
-
商家门店连锁关系不是固定的,A 门店数据今天属于 AA 连锁,明天可能会变成 BB 连锁。
-
数据展现多人多面,权限不同展现结果不同。
-
数据变更非常频繁,一条数据最少也会经过五六次变更操作。
-
实时报表展现的不仅是当天数据,涉及到挂帐、垮天营业、不结账等复杂状况,生产数据的生命周期往往会超过一个月以上。
如果用 MySQL 作为报表存储引擎的话,一个门店所属连锁总部变更,相当于分库的路由值产生了变化,意味着需要对这家店的数据进行全量迁移,这是个灾难性的事情,我们希望连锁只是个属性,而不用受到 Sharding Key 的制约导致的一地鸡毛。
开始的解决方案
我们的业务数据是构建在 MySQL 之上,按照业务和商家维度进行分库。利用 Otter 订阅业务数据,进行数据整理归并到 Apache Solr[1] 中,输出分析、统计报表所需要的数据。然而随着业务的快速发展以及客户定制化需求不断增加,Solr 的瓶颈从一张白纸慢慢地被填充。
-
不断的添加检索维度,需要不停的对索引进行 Full Build,Solr 的 Full Build 成本慢慢地高成了一座大山。
-
为保障数据精准,Solr 的 Full Build 必须隔段时间操作一次。
-
随着业务蓬勃发展,数据更新频率越来越高、范围时间内更新的数据条数越来越多,面对 Solr GC 这个问题,我们对数据更新做了窗口控制,一条数据的更新延迟到了 10 秒钟。
-
Solr 的故障恢复时间过长,严重影响业务可用性。
-
Solr 很好,但是对于要求能灵活定制、数据即时、维度复杂的报表业务来说,他还不够好。
引入 TiDB
在引入 TiDB 之前,我们也评估和使用过 Greenplum,但是发现并发实时写入的性能无法满足我们的业务承载,在机缘巧合之下认识了 TiDB 同学们,经过了一段时间熟悉、测试和研究之后,我们意识到 TiDB 就是我们想要的产品,于是就开始在实际环境中使用 TiDB 来构建实时报表系统。
特别要赞美下 TiDB 的软件太棒了,国内开源软件无出其右,天然的高可用,本身减少了很多运维工作,Ansible 多节点、多组件一键部署,业务无感知滚动升级,特别是把监控也嵌合到软件本身里,让我们追踪、定位问题异常清晰明了,大大缩减了排查成本。
当然 TiDB 的优点很多:
-
首先解决了繁琐的分库分表以及无限水平扩展问题,并且能保证事务特性。
-
其次故障自恢复,计算、存储全无单点。
-
还有 TiDB 在做 DDL 操作时候,基本不影响业务使用,这个对我们经常调整表结构的业务来说,大大加快了迭代速度,在线 DDL 不再是一件奢侈的事情。
-
TiDB 通过下推到存储节点进行并行计算等技术,在数据量大、同时不影响写入的情况下,能非常好的满足各种统计查询响应时间要求。
总之,TiDB 很好的解决了我们之前在实时报表碰到了各种痛点,让我们终于不用为业务方的每项决策和用户的需求而绞尽脑汁和痛苦不堪。
TiDB 集群总体配置如下:2*TiDB、3*TiKV、3*PD
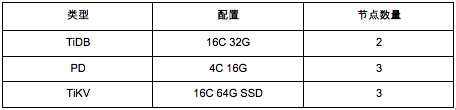
TiDB 使用体验
我们基于 TiDB 的实时报表系统稳定运行了一个多月,目前实时报表承载的日数据更新量在一亿以上,高峰时期 TiDB 写入 QPS 高于 4000,百级读 QPS ,读流量基本上是统计类 SQL, 比较复杂,最多包含十几张表的关联查询。TiDB 不管从性能、容量还是高可用性以及可运维性来说,完全超出了我们的预期。TiDB 让我们的业务开发回到了业务本质,让简单的再简单,开发不需要再拆东墙补西墙忙于数据爆发带来的各种手忙脚乱。
整体数据库架构图:
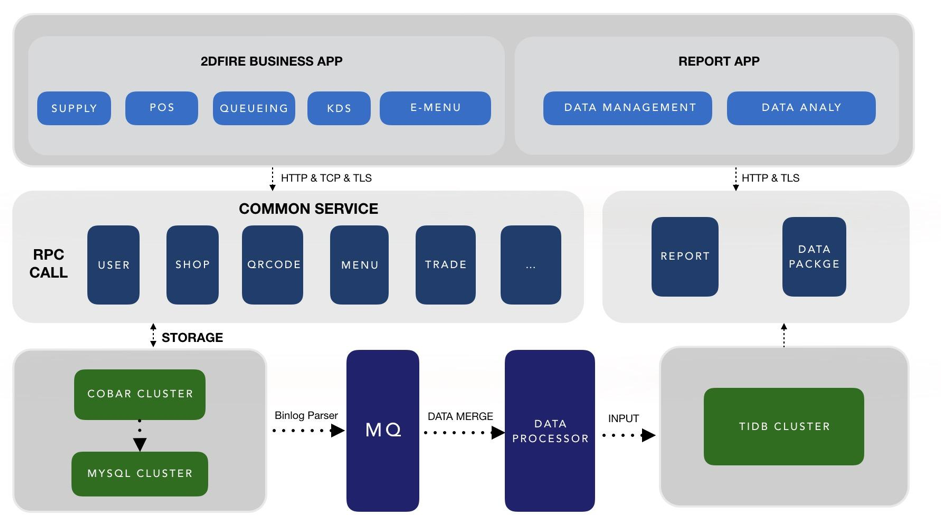
在 TiDB 使用中的几点注意事项
一些注意事项,TiDB 的官方文档写的非常详细全面了,这里我再画蛇添足几点个人觉得非常重要的几项:
-
TiDB 对 IO 操作的延迟有一定的要求,所以一定要本地 SSD 盘。我们一开始在一个集群中使用了云 SSD 盘,发现性能抖动非常厉害,特别是扩容缩容会导致业务基本不可用。
-
删除大数据的时候,用小数据多批量方式操作,我们现在每批次是小于 1000 条进行删除。
-
在大批量数据导入后,务必先操作 analyze table${table_name}。
-
TiDB 开发非常活跃,版本迭代非常快,升级的时候先在非生产环境演练下业务,特别是一些复杂 SQL 的场景。
后续计划
在接入一个业务实时报表后,我们对 TiDB 越来越了解,后续我们计划对 TiDB 进行推广使用,具体包括:
-
把公司所有实时报表以及统计结果都逐渐迁移到 TiDB 中。
-
对业务进行分类,大表、多表关联的复杂场景准备开始使用 TiSpark,结合现有 TiDB,会大大简化目前整个数据产品、架构,同时大大解放运维。
-
中期会考虑将 OLTP 的业务迁入到 TiDB。
最终通过 TiDB 构造成一个同时兼容分析型和事务型(HTAP)的统一数据库平台。